
探索的データ解析
探索的データ解析(たんさくてきデータかいせき、英: exploratory data analysis、EDA)とは、データセットを解析してその主な特徴を要約する、統計学における手法であり、しばしば統計グラフィックスやその他のデータ可視化手法を使用する。統計モデルは使っても使わなくてもよいが、EDAは主に形式的なモデル化を超えてデータが何を語ってくれるかを見るためのもので、それによって従来の仮説検定と対比される。探索的データ解析は、1970年以降、ジョン・テューキーによって推進されており、統計学者に対して、データを探索し新しいデータ収集や実験につながるような仮説を立てることを奨励している。EDAは初期データ解析(IDA)とは異なるもので、IDAは、モデル適合や仮説検定に必要な前提条件を確認したり、欠損値の処理や、必要に応じて変数を変換を行うことに焦点を絞っている[1][2]。EDAにはIDAが含まれる。
概要
[編集]テューキーは1961年にデータ解析の定義を、『データを分析するための手順、その手順による結果を解釈する技術、分析をより容易に、正確または精密にするためのデータ収集の計画方法、そしてデータ分析に適用される(数理)統計学のすべての手続きと結果である。』と説明した[3]。
EDAに対するテューキーの擁護は、特にベル研究所のS言語のような、統計計算パッケージの開発を後押しした。プログラミング言語Sは、後に、S-PLUSやRシステムに影響を与えた。この一連の統計計算環境は、大幅に改善された動的な可視化機能を備えており、統計学者は、さらに研究する価値のあるデータの異常値、傾向、パターンを識別することができた。
テューキーのEDAは、統計理論における他の2つの発展、すなわちロバスト統計学とノンパラメトリック統計学に関連しており、これらはいずれも統計モデルの定式化の誤りに対する統計的推測の感度を低減させるものであった。テューキーは、数値データについて、五数要約 (英語版:en) (2つの極値(最大と最小)、中央値、および四分位値)の使用を推進した。なぜなら、中央値と四分位値は経験分布関数であり、平均値と標準偏差とは異なり、すべての分布に対して定義され、さらに、四分位値と中央値は従来の要約(平均値と標準偏差)よりも、歪んだ分布や裾の重い分布に対してよりロバスト(堅牢)だからである。S、S-PLUS、Rの各パッケージには、モーリス・クヌーイュとテューキーのジャックナイフ法や、エフロンのブートストラップ法など、ノンパラメトリックで(多くの問題に対して)頑健な、リサンプリング統計を用いたルーチンが含まれている。
探索的データ解析、ロバスト統計、ノンパラメトリック統計、および統計プログラミング言語の開発により、統計学者による科学的および工学的な問題への取り組みが容易になった。このような問題には、ベル研究所に関係する半導体の製造と通信ネットワークの理解が含まれている。これらの統計学の発展はすべてテューキーが唱えたもので、統計的仮説検定に関する解析理論、特に指数型分布族に対するラプラシアン強調を補完するように設計された[4][訳語疑問点]。
展開
[編集]
1977年、ジョン・W・テューキーは Exploratory Data Analysis(探索的データ解析)という本を著した[5]。テューキーは、統計学においては統計的仮説検定(確証的データ解析)が重視されすぎており、データを用いて検定すべき仮説を示唆することにもっと重点を置くべきと主張した。特に彼は、2つの種類の分析を混同して同じデータセットに適用すると、データから示唆される仮説検定をする際に内在する問題により、系統的バイアスにつながる可能性があると考えた。
EDAの目的は次のとおりである。
- データから予期しない発見を可能にする。
- 観察された現象の原因に関する仮説を提案する。
- 統計的推測の基礎となる仮定を評価する。
- 適切な統計ツールや技術の選択を支援する。
- サンプリング調査や実験を通じて、さらなるデータ収集の基礎を提供する[6]。
多くのEDA技術はデータマイニングに取り入れられている。それらはまた、統計的思考を導入する方法として、若い学生にも教えられている[7]。
技術とツール
[編集]EDAに有効なツールは多数あるが、EDAの特徴は特定の技術よりもその姿勢に見られる[8]。
EDAで使われる代表的なグラフ技法はつぎのとおりである。
- 箱ひげ図
- ヒストグラム
- 多変量チャート
- ランチャート(実行流れ図)
- パレート図
- 散布図(2D/3D)
- 幹葉図
- 平行座標
- オッズ比 (en:英語版#Example)
- ターゲット射影追跡
- ヒートマップ
- 棒グラフ
- 値変遷グラフ(ホライゾングラフ)
- PhenoPlot[9]、チャーノフの顔などのグリフベースの可視化手法。
- グランドツアー、ガイドツアー、マニュアルツアーなどの投影手法。
- これらのプロットの対話型バージョン
次元削減:
- 多次元尺度法
- 主成分分析(PCA)
- マルチリニア主成分分析
- 非線形次元削減(NLDR)
- 相関イコノグラフィ
代表的な定量的手法:
歴史
[編集]EDAのアイデアの多くは、以前の著者にさかのぼることができる。たとえば:
- フランシス・ゴルトンは順序統計量と分位数を力説した。
- アーサー・リヨン・ボウリーは、ステムプロットと五数要約の前身を使用した(ボウリーは実際には、中央値とともに、極値、十分位、四分位を含む「七数要約」を使用していた[注釈 1][10]。彼は「最大値と最小値、中央値、四分位、2つの十分位」を「七位置」として定義した)。
- アンドリュー・エーレンバーグはデータ削減の原理を明確にした(同名の彼の本を参照)。
オープン大学の講座「Statistics in Society(社会における統計学)」(MDST 242)では、上記の考え方を取り入れ、ゴットフリート・ネーターの研究と統合し、コイン投げや中央値検定による統計的推論を導入した。
事例
[編集]EDAから得られる知見は、主要な分析課題と(統計学的に)関係しない。説明のために、Cookらの例で考えてみよう。この分析課題は、食事会のパーティーがウェイターに渡すチップ額を最もよく予測する変数を見つけることである[11]。この課題のために収集されたデータで利用可能な変数は、チップ額、合計請求額、支払い者の性別、喫煙/禁煙席、時間帯、曜日、食事会の規模である。主要な分析課題は、チップ率を応答変数とする回帰モデルの適合によって取り組まれる。その適合モデルは、
- (チップ率) = 0.18 - 0.01 × (パーティーの規模)
であり、食事会の人数が1人増える(請求額が高くなる)と、チップ率は平均で1%減少することを表す。
ただし、このデータを調べてみると、このモデルで説明できない別の興味深い特徴があることが明らかになる。
-
 チップ額のヒストグラム。ここでビン(箱)は1ドル刻み。値の分布は、右に偏った単峰性であり、小さく非負の量の分布でよく見られる。
チップ額のヒストグラム。ここでビン(箱)は1ドル刻み。値の分布は、右に偏った単峰性であり、小さく非負の量の分布でよく見られる。 -
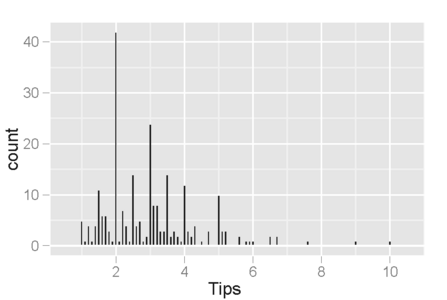 このチップ額のヒストグラムは0.10ドル刻みのビンを用いた。興味深い現象が見られる。ピークは、1ドルと半ドルの金額で発生する。これは、顧客が概数(端数のない数)をチップとして選ぶことに起因している。この現象は、ガソリンなど別の種類の買い物にも共通している。
このチップ額のヒストグラムは0.10ドル刻みのビンを用いた。興味深い現象が見られる。ピークは、1ドルと半ドルの金額で発生する。これは、顧客が概数(端数のない数)をチップとして選ぶことに起因している。この現象は、ガソリンなど別の種類の買い物にも共通している。 -
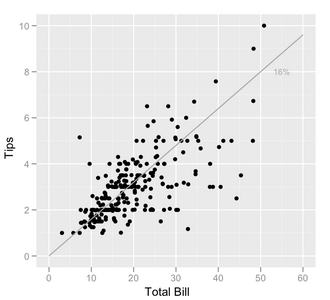 チップと請求額の散布図。直線より下の打点は、(その請求額に対して)予想より低いチップに対応し、直線より上の打点は、予想より高いチップに対応する。読者は、締まって隙間のない正の線形関連が見られると予想したかもしれないが、チップの額によってばらつきがあることがわかる。特に、左上よりも右下の方が直線から遠く離れた打点が多く、非常に気前のいい客よりも非常に財布の紐が堅い客の方が多いことを示している。
チップと請求額の散布図。直線より下の打点は、(その請求額に対して)予想より低いチップに対応し、直線より上の打点は、予想より高いチップに対応する。読者は、締まって隙間のない正の線形関連が見られると予想したかもしれないが、チップの額によってばらつきがあることがわかる。特に、左上よりも右下の方が直線から遠く離れた打点が多く、非常に気前のいい客よりも非常に財布の紐が堅い客の方が多いことを示している。 -
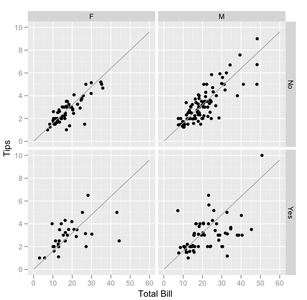 支払い者の性別と喫煙席の有無で区切った、チップ額対会計額の散布図を示す。喫煙席の方が、渡すチップにより多くのばらつきがある。男性は(少数の)より高い請求額を支払う傾向があり、女性の非喫煙者は非常に一貫したチップを支払う傾向がある(サンプルに示された3つの顕著な例外を除く)。
支払い者の性別と喫煙席の有無で区切った、チップ額対会計額の散布図を示す。喫煙席の方が、渡すチップにより多くのばらつきがある。男性は(少数の)より高い請求額を支払う傾向があり、女性の非喫煙者は非常に一貫したチップを支払う傾向がある(サンプルに示された3つの顕著な例外を除く)。




この実験は、こうした他の傾向を調査するように設計されたわけではないが、プロットから学べることは回帰モデルで示されるものとは異なっている。データを探索することによって発見されたパターンは、事前に予想されていなかったかもしれないチップに関する仮説を示唆している。それは、仮説を正式に述べ、新しいデータを収集することによって検証される、興味深い追跡実験につながる可能性がある。
ソフトウェア
[編集]- JMP- SAS InstituteのEDAパッケージ。
- KNIME - Eclipseをベースとしたオープンソースのデータ探索プラットフォーム。
- Minitab - 産業や企業で広く使われているEDAおよび一般的な統計パッケージ。
- Orange - オープンソースのデータマイニングおよび機械学習ソフトウェアスイート。
- Python - データマイニングや機械学習で広く利用されているオープンソースのプログラミング言語。
- R - 統計計算およびグラフィックスのためのオープンソースのプログラミング言語。Pythonとともに、データサイエンスで最も人気のある言語の1つ。
- TinkerPlots - 小学校高学年から中学生向けのEDAソフトウェア。
- Weka - ターゲット射影追跡などの可視化およびEDAツールを含むオープンソースのデータマイニングパッケージ
- Visplore - 大規模な時系列データのためのEDAソフトウェア
参照項目
[編集]- アンスコムの例 - 探索の大切さを示す
- データドレッジング- 統計的に有意な結果を得た結果だけを報告する、データ分析の悪用
- 予測的分析 - 現在および過去の事実をもとに、将来または未知の出来事について予測する分析手法
- 構造化データ解析 (統計学) - 与えられたデータに適合する構造を探索し、比較、予測、操作などに用いる分析手法
- 構成頻度分析 - 偶然に予想されるよりも著しく多い、または少ないパターンを検出し、構造に関する洞察を得る分析手法
- 記述統計量 - 標本の分布の特徴を定量的に記述し要約する統計学的な値
脚注
[編集]- ^ Elementary Manual of Statistics (第3版, 1920、p. 62)を参照
- ^ Chatfield, C. (1995). Problem Solving: A Statistician's Guide (2nd ed.). Chapman and Hall. ISBN 978-0412606304
- ^ Baillie, Mark; Le Cessie, Saskia; Schmidt, Carsten Oliver; Lusa, Lara; Huebner, Marianne; Topic Group "Initial Data Analysis" of the STRATOS Initiative (2022). “Ten simple rules for initial data analysis”. PLOS Computational Biology 18 (2): e1009819. doi:10.1371/journal.pcbi.1009819. PMC 8870512. PMID 35202399.
- ^ John Tukey-The Future of Data Analysis-July 1961
- ^ Morgenthaler, Stephan; Fernholz, Luisa T. (2000). “Conversation with John W. Tukey and Elizabeth Tukey, Luisa T. Fernholz and Stephan Morgenthaler”. Statistical Science 15 (1): 79–94. doi:10.1214/ss/1009212675.
- ^ Tukey, John W. (1977). Exploratory Data Analysis. Pearson. ISBN 978-0201076165
- ^ Behrens-Principles and Procedures of Exploratory Data Analysis-American Psychological Association-1997
- ^ Konold, C. (1999). “Statistics goes to school”. Contemporary Psychology 44 (1): 81–82. doi:10.1037/001949.
- ^ Tukey, John W. (1980). “We need both exploratory and confirmatory”. The American Statistician 34 (1): 23–25. doi:10.1080/00031305.1980.10482706.
- ^ Sailem, Heba Z.; Sero, Julia E.; Bakal, Chris (2015-01-08). “Visualizing cellular imaging data using PhenoPlot” (英語). Nature Communications 6 (1): 5825. Bibcode: 2015NatCo...6.5825S. doi:10.1038/ncomms6825. ISSN 2041-1723. PMC 4354266. PMID 25569359.
- ^ Elementary Manual of Statistics (3rd edn., 1920)https://archive.org/details/cu31924013702968/page/n5
- ^ Cook, D. and Swayne, D.F. (with A. Buja, D. Temple Lang, H. Hofmann, H. Wickham, M. Lawrence) (2007) ″Interactive and Dynamic Graphics for Data Analysis: With R and GGobi″ Springer, 978-0387717616
参考書目
[編集]- Andrienko, N & Andrienko, G (2005) Exploratory Analysis of Spatial and Temporal Data. A Systematic Approach. Springer. ISBN 3-540-25994-5
- Cook, D. and Swayne, D.F. (with A. Buja, D. Temple Lang, H. Hofmann, H. Wickham, M. Lawrence) (2007-12-12). Interactive and Dynamic Graphics for Data Analysis: With R and GGobi. Springer. ISBN 9780387717616
- Hoaglin, D C; Mosteller, F & Tukey, John Wilder (Eds) (1985). Exploring Data Tables, Trends and Shapes. ISBN 978-0-471-09776-1
- Hoaglin, D C; Mosteller, F & Tukey, John Wilder (Eds) (1983). Understanding Robust and Exploratory Data Analysis. ISBN 978-0-471-09777-8
- Inselberg, Alfred (2009). Parallel Coordinates:Visual Multidimensional Geometry and its Applications. London New York: Springer. ISBN 978-0-387-68628-8
- Leinhardt, G., Leinhardt, S., Exploratory Data Analysis: New Tools for the Analysis of Empirical Data, Review of Research in Education, Vol. 8, 1980 (1980), pp. 85–157.
- Martinez, W. L.; Martinez, A. R. & Solka, J. (2010). Exploratory Data Analysis with MATLAB, second edition. Chapman & Hall/CRC. ISBN 9781439812204
- Theus, M., Urbanek, S. (2008), Interactive Graphics for Data Analysis: Principles and Examples, CRC Press, Boca Raton, FL, ISBN 978-1-58488-594-8
- Tucker, L; MacCallum, R. (1993). Exploratory Factor Analysis. [1]
- Tukey, John Wilder (1977). Exploratory Data Analysis. Addison-Wesley. ISBN 978-0-201-07616-5
- Velleman, P. F.; Hoaglin, D. C. (1981). Applications, Basics and Computing of Exploratory Data Analysis. ISBN 978-0-87150-409-8
- Young, F. W. Valero-Mora, P. and Friendly M. (2006) Visual Statistics: Seeing your data with Dynamic Interactive Graphics. Wiley ISBN 978-0-471-68160-1
- Jambu M. (1991) Exploratory and Multivariate Data Analysis. Academic Press ISBN 0123800900
- S. H. C. DuToit, A. G. W. Steyn, R. H. Stumpf (1986) Graphical Exploratory Data Analysis. Springer ISBN 978-1-4612-9371-2
外部リンク
[編集]- Carnegie Mellon University – free online course on Probability and Statistics, with a module on EDA
- Exploratory data analysis chapter: engineering statistics handbook
| 典拠管理データベース: 国立図書館 |
|---|