
Bulldozer (マイクロアーキテクチャ)
| 生産時期 | 2011年から |
|---|---|
| 設計者 | AMD |
| 生産者 | GLOBALFOUNDRIES |
| プロセスルール | 32 nm |
| 命令セット | AMD64 |
| ソケット |
Socket AM3+ Socket C32 Socket G34 |
| パッケージ |
AMD FX Opteron |
| 前世代プロセッサ | AMD K10 |
| 次世代プロセッサ | Piledriver |
Bulldozer(ブルドーザー)とは、AMDのx64実装のマイクロプロセッサアーキテクチャである。デスクトップ向けAMD FXとサーバー向けOpteronに採用された。
Bulldozerは、K10 マイクロアーキテクチャの次世代CPUコアに与えられたコードネームのひとつで、TDPは10Wから125Wを目標としていた。このアーキテクチャはゼロから完全に新しく作られた物で、AMDは、HPCアプリケーションに Bulldozerコアを用いる事で、1Wあたりの性能を劇的に向上させる事ができると主張している。
概要
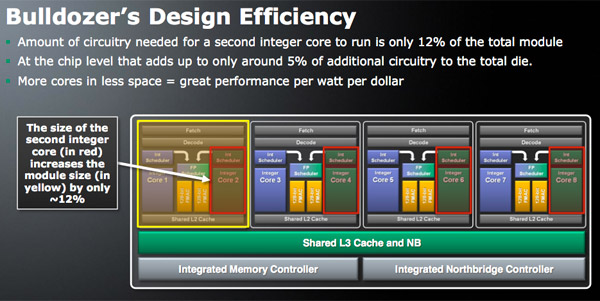
[編集]AMDによると、BulldozerベースCPUはグローバルファウンドリーズ32nm SOIプロセス技術に基づき、マルチタスク性能のために賛否が分かれるDECのアプローチを再利用した。プレスノートによれば、「パフォーマンスをスケーリングするためにチップ上で簡単に複製できる非常にコンパクトで、ユニット数の多い設計を提供するためコンピューターリソースの専占と共有のバランスを取った」[1]。言い換えれば、マルチコア設計に自然に忍び寄る「冗長」要素のいくつかを排除することにより、AMDは、より少ない電力を使用しながらハードウェア機能をより有効に活用することを望んでいた。 HKMG(High-k/Metal Gate)を使用して32nmSOI上に構築されたBulldozerベースの実装は、サーバーとデスクトップの両方で2011年10月に到着した。サーバーセグメントにはコードネームInterlagos(Socket G34用16コア)デュアルチップとコードネームValencia(Socket C32用4、6、または8コア)シングルチップOpteronプロセッサが含まれていたが一方、Zambezi(4、6、および8コア)は、Socket AM3+のデスクトップを対象としていた[2][3]。BulldozerはAMDがK8プロセッサを発売した2003年以来AMDプロセッサアーキテクチャ初の主要な再設計であり、1つの256ビットFPUに組み合わせることができる2つの128ビットFMA対応FPUも備えている。この設計には、それぞれ4つのパイプラインを持つ2つの整数クラスターが付属している(フェッチ/デコードステージは共有される)。Bulldozerはまた、新しいアーキテクチャに共有L2キャッシュを導入した。 AMDはこの設計を「モジュール」と呼んでいる。 16コアプロセッサの設計では、これらの「モジュール」のうち8つを備えているが[4]、オペレーティングシステムは各「モジュール」を2つの論理コアとして認識する。 モジュラーアーキテクチャは、マルチスレッド対応共有L2キャッシュと同時マルチスレッディングを使用するFlexFPUで構成されている。 2つの仮想同時スレッドが単一の物理コアのリソースを共有するIntelのハイパースレッディングとは対照的に、各物理整数コアはモジュールごとに2つシングルスレッドである[5][6]。
特徴
[編集].png)
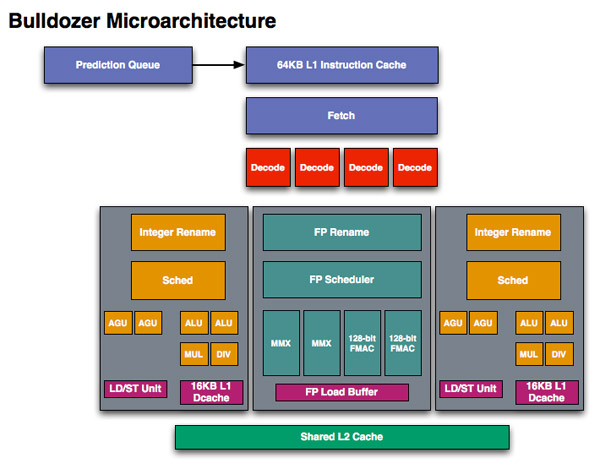
2つの整数演算ユニット、1つのFPU、1つの命令デコーダ、1つのL2キャッシュなどからなるモジュール(Bulldozerコア)を基本単位として構成されるクラスタードアーキテクチャとなる。命令キャッシュからデコーダまでのフロントエンドと、FPU及びL2キャッシュが2つの整数演算ユニットで共有されており、2つの整数演算ユニットと2つのL1データキャッシュのみがBulldozerコア毎(ごと)に独立している構造になっている。そのため、(整数のみ)完全なデュアルコアと(FPUとその他が)SMTと中間的な構造である。その他特徴的な点として、浮動小数点の積和算をサポートしている。1サイクルに従来命令換算で、4つの128ビット演算を行えるため、モジュール単位でPhenom II 1コアと比較して2倍のスループットを得られる。整数演算装置が2/3の性能で、IPCがK10より下がるため、クロックを上げて性能を補う、近年のAMDには珍しいスピードデーモン寄りのアーキテクチャとなり、K10と比べてクロックが25%ほど上昇している。
L2キャッシュは1モジュールにつき2MBとなる。デスクトップ向けの Zambezi は、L3は8MBで、メモリはDDR3-1866デュアルチャネルに対応する。
.PNG)
液体ヘリウムを使用したオーバークロックを行った結果、8.461GHzを達成し、ギネス世界記録となった[7][8]。
アーキテクチャの詳細
[編集]Bulldozerコア
[編集]Bulldozerはプロセッサのある一部は2つのスレッドの間で共有され、またある一部はスレッドごとに固有である技法、「クラスタード・マルチスレッディング(CMT)」を駆使する。型破りなマルチスレッディングへのそのようなアプローチの以前の例は、2005年のサン・マイクロシステムズのUltraSPARC T1プロセッサにまで遡ることができる。 ハードウェアの複雑さと機能性の観点から、ブルドーザーCMTモジュールは、整数演算能力においてデュアルコアプロセッサと、浮動小数点演算能力の点においては、同じCMTモジュールで実行されている両方のスレッドの浮動小数点命令でコードが飽和しているかどうかそして、FPUが128ビットまたは256ビットの浮動小数点演算を実行しているかどうかに応じて、シングルコアまたはハンディキャップのあるデュアルコアプロセッサのいずれかと同等である。この理由は、つまり同じモジュール内に、2つの整数コアごとに、128ビットFMAC実行ユニットの対からなる単一のFPUが存在するためである。
CMTは、ある意味でSMTと単純だが、類似した設計哲学である; どちらの設計も、実行ユニットを効率的に利用しようとする; どちらの方法でも、2つのスレッドが一部の実行パイプラインをめぐって競合すると、1つかそれ以上のスレッドのパフォーマンスが低下する。専用の整数コアにより、Bulldozerファミリーモジュールは完全に整数であるか、整数と浮動小数点の計算が混在するコードのセクションで、ほぼデュアルコアの、デュアルスレッドプロセッサのように動作した; ただし、SMTは共有浮動小数点パイプラインを使用するため、モジュールは、浮動小数点命令で飽和スレッドのペアについてシングルコアのデュアルスレッドSMTプロセッサ(SMT2)と同様に振る舞う。(これらの最後の2つの比較はどちらもプロセッサがそれぞれ、整数単位と浮動小数点単位で、等幅で同等能力のある実行コアを持っていることを前提としている。)
CMTとSMTはどちらも整数と浮動小数点コードをスレッドのペアで実行しているときに最大の効果を発揮する。CMTは両方共に整数コードから成るスレッドのペアで作業している間、最高の効果を維持し、一方SMTの下では、整数実行ユニットの競合により一方または両方のスレッドのパフォーマンスが低下する。CMTの欠点はシングルスレッドの場合にアイドル状態の整数実行ユニットの数が増えることである。シングルスレッドの場合、CMTはモジュール内の整数実行ユニットの最大半分を使用するように制限されているが、SMTはそのような制限を課していない。2つのCMTコアと同じ幅で高速な整数回路を備えた大規模なSMTコアは、理論上、シングルスレッドの場合に瞬間的に最大2倍の整数パフォーマンスを発揮する。(一般的なコード全体としてより現実的には、ポラックの法則はのスピードアップ係数、つまりパフォーマンスの約40%の向上を推定する。)

CMTプロセッサと一般的なSMTプロセッサは、スレッドのペア間でL2キャッシュを効率的に共有して使用する点で類似している。
- モジュールは、2つの「従来の」x86アウトオブオーダー処理コアのカップリングで構成されている。処理コアは、パイプラインの初期段階(例えば L1命令(キャッシュ)、フェッチ、デコードなど)、FPU、およびモジュールの残りの部分と共にL2キャッシュを共有する。
- 各モジュールには、次の独立したハードウェアリソースがある[9][10]。
- 1コアあたり16KBの4ウェイL1データ(キャッシュ)(ウェイ予測)および1モジュールあたり2ウェイ64KBのL1命令(キャッシュ)、2つのコアのそれぞれに1ウェイ[11][12][13]
- 1モジュールごとに2MBのL2キャッシュ(2つの整数コア間で共有)
- Write Coalescing(合体) Cache(W.C.C.)[14]は、BulldozerマイクロアーキテクチャにおいてL2キャッシュの一部である特別なキャッシュである。 1モジュール内の両方のL1データキャッシュからのストアは、W.C.C.を通過し、そこでバッファリングおよび合体される。W.C.C.のタスクは、L2キャッシュへの書き込み数を減らすことである。
- 2つの専用整数コア
- モジュールごとに2つの対称128ビットFMAC(融合積和演算機能つき)浮動小数点パイプラインは整数コアの1つがAVX命令と2つの対称x87/MMX/SSE対応浮動小数点パイプラインをディスパッチして、SSE2非最適化ソフトウェアとの下位互換性を確保する場合、1つの大きな256ビット幅のユニットに統合できる。各FMACユニットは、可変レイテンシーでの除算および平方根演算も可能である。
- 存在するすべてのモジュールは、高度なデュアルチャネルメモリサブシステム(IMC – 統合メモリコントローラー)と同様にL3キャッシュを共有する。
- 1つのモジュールには、(2MBの共有L2キャッシュを含む)オロチダイ上の30.9mm²のエリアに2億1300万個のトランジスタがある[16]。
- Bulldozerのパイプラインの深さは(同様にPiledriverとSteamrollerも)、前身のK10コアの12サイクルと比較して、20サイクルである[17]。
より長いパイプラインにより、Bulldozerファミリーのプロセッサは、前身のK10と比較してはるかに高いクロック周波数を達成することができた。これにより周波数とスループットが向上したが、パイプラインが長くなると、レイテンシが増加し、分岐予測の予測ミスによるペナルティが増加した。
- Bulldozer整数コアの幅(4 = (2ALU + 2AGU))は、K10コアの幅(6 = (3ALU + 3AGU))よりもいくらか狭くなっている。BobcatとJaguarも4つのワイド整数コアを使用したが、まだより軽い実行ユニットで:1つのALU、1つの単純なALU、1つのロードAGU、1つのストアAGUである[18]。
Jaguar、K10、およびBulldozerコアの(命令)発行幅(およびサイクルごとの命令実行ピーク)は、それぞれ2、3、および4である。これにより、BulldozerはJaguar/Bobcatと比較してよりスーパースカラーのデザインになった。しかしながら、(第1世代の設計には改良と最適化がないことに加えて)K10のコアがやや広いため、Bulldozerアーキテクチャは通常、前身のK10と比較してやや低いIPCで実行された。BulldozerファミリーのIPCがPhenom IIなどのK10プロセッサのIPCを明らかに上回り始めたのは、PiledriverとSteamrollerで行われた改良が行われるまではなかった。
- 2レベルの分岐ターゲットバッファ(BTB)[19]
- 条件文用ハイブリッド予測器
- 間接予測器
拡張命令セット
[編集]- 256ビット浮動小数点演算、およびSSE4.1、4.2、AES、CLMULをサポートするIntelのAdvanced Vector Extensions(AVX)命令セットのサポート, 及びAMDが提案した将来性ある128ビット命令セット(XOP、FMA4、およびF16C)[20], ただしこれは、AMDによって以前に提案されたAVXコーディングスキームとの互換性があるSSE5命令セットと同じ機能を備えている。
プロセス技術とクロック周波数
[編集]- 第1世代グローバルファウンドリーズHigh-Kメタルゲート(HKMG)によって実装される11層メタルレイヤー32nm SOIプロセス
- TurboCore2パフォーマンスブーストはTDPの制限内で、すべてのスレッドがアクティブな場合(ほとんどのワークロードの場合)にクロック周波数を最大500MHzまで、スレッドの半分がアクティブな場合に最大1GHzまでクロック周波数を上げる[21]。
- チップは0.775〜1.425Vで動作し、3.6GHz以上のクロック周波数を実現する[22]。
- TDP: 最小25ワット〜最大140ワット
キャッシュとメモリ・インタフェース
[編集]- 最大8MBのL3は同じシリコンダイ上のすべてのコア間で共有される(デスクトップセグメントの4コアの場合は8MB、サーバーセグメントの8コアの場合は16MB)、それぞれ2MBの4つのサブキャッシュに分割され、1.1125Vで2.2GHz動作が可能である[23]
- DDR3-1866までのネイティブDDR3メモリをサポート[24]
- デスクトップおよびサーバー/ワークステーション用Opteron 42xx "Valencia"はデュアルチャネルDDR3統合メモリコントローラー[25]; サーバー/ワークステーション用Opteron 62xx "Interlagos"はクワッドチャネルDDR3統合メモリコントローラー[26]である
- AMDはチャネルごとにDDR3-1600の2つのDIMMのサポートを主張する。シングルチャンネル上のDDR3-1866の2つのDIMMは、1600にダウンクロックされる。
I/Oおよびソケット・インターフェース
[編集]- HyperTransportテクノロジー リビジョン3.1(3.2GHz、6.4GT/s、25.6GB/sそして16ビット幅のリンク)[2010年3月にSocket G34のOpteronプラットホームにて「Magny-Cours」が、そして2010年6月Socket C32のOpteronプラットホームにて「Lisbon」がHY-D1リビジョンになって最初に実装された。]
- Socket AM3+ (AM3r2)
- サーバーセグメントには、既存のSocket G34(LGA1974)とSocket C32(LGA1207)が使用される。
OSの対応
[編集]旧来のどのアーキテクチャとも異なる構成なのでIntel HTTの時と同じようにOSスケジューラの対応が必要となる場合がある。
Windows
[編集]Windowsのスケジューラは空いているコアに対してスレッドを割り振るが、対策前のWindowsでは「Bulldozerコア」の特性(フロントエンドやFPUの共有)を考慮していないため、同一モジュール内かどうかを考慮せずにスレッドを割り振る。このために空いているモジュールがあるにもかかわらず、同一モジュールにスレッドを割り振ってフロントエンドやFPUがボトルネックになり性能低下が起こる事があった。
マイクロソフトは2012年1月にKB2645594とKB2646060のパッチを公開しこの問題に対応した。KB2645594はBulldozerコア1基を物理1コア論理2コアと見立てるように修正するパッチで、KB2646060はKB2645594の副作用でBulldozerコアが頻繁にC6ステートに入ってしまい,結果,マルチスレッド化があまり進んでいない環境で性能が低下する問題を修正するパッチである。
このパッチ群により性能低下への対応は行われたが、対策後のWindowsからは 物理コア数=Bulldozerコア数のSMTタイプCPUとして扱われるため、本来の性能を発揮しているかどうかは未知数である。
AMDはWindows 8でBulldozerへの最適化がなされるようマイクロソフトと協力しているという。
Linux
[編集]1モジュールあたり1コア2スレッドのSMTプロセッサとして扱われる。
虚偽広告訴訟
[編集]2015年11月、AMDはBulldozerチップの仕様を不実表示したとしてカリフォルニア消費者法的救済法および不公正競争法に基づいて訴えられた。10月26日にカリフォルニア北部地区連邦地方裁判所に提起された集団訴訟では、各Bulldozerモジュールは実際には真のデュアルコア設計ではなく、いくつかのデュアルコア特性を備えた単一のCPUコアであると主張していた[30]。
2019年8月、AMDは12.1百万ドルで訴訟を和解することに合意した[31][32]。
改良
[編集]Piledriver
[編集]Piledriver は二世代目の Bulldozer として2012年に発表された。IPC と動作周波数の向上が図られた。
Steamroller
[編集]Steamroller は三世代目の Bulldozer として2013年に発表された。
Excavator
[編集]Excavator は四世代目の Bulldozer として2015年に発表された。AVX2などの命令がサポートされた。
脚注
[編集]- ^ AMD Sets New Mark in x86 Innovation with First Detailed Disclosures of Two New Core Designs, AMD, (August 24, 2011), p. 1 September 18, 2011閲覧。
- ^ Analyst Day 2009 Summary, AMD, (November 11, 2009) 2009年11月14日閲覧。
- ^ AMD bestätigt: "Zambezi" ist inkompatibel zum Sockel AM3, Planet3dnow.de 2012年1月23日閲覧。
- ^ Analyst Day 2009 Presentations, AMD, (November 11, 2009) 2009年11月14日閲覧。
- ^ http://cdn3.wccftech.com/wp-content/uploads/2013/07/AMD-Steamroller-vs-Bulldozer.jpg
- ^ “AMD unveils Flex FP - bit-tech.net”. bit-tech.net. 2021年7月21日閲覧。
- ^ (英語) Overclocking World Record Broken - IGN 2021年7月21日閲覧。
- ^ Oct 29th, btarunr. “AMD OC Record Broken, Still Powered by AMD FX-8150” (英語). TechPowerUp. 2021年7月21日閲覧。
- ^ Bulldozer microarchitecture block, AnandTech, (August 24, 2010)
- ^ Bulldozer module functional schematic, AMD, (August 24, 2010)
- ^ More On Bulldozer, Tomshardware.com, (2010-08-24) 2012年1月23日閲覧。
- ^ AMD Reveals Details About Bulldozer Microprocessors, AMD Reveals Details About Bulldozer Microprocessors, Xbitlabs.com 2012年1月23日閲覧。
- ^ Real World Technologies (2010-08-26), AMD's Bulldozer Microarchitecture, Realworldtech.com 2012年1月23日閲覧。
- ^ David Kanter (August 26, 2010). “AMD’s Bulldozer Microarchitecture Memory Subsystem Continued”. Real World Technologies. 2017年4月2日閲覧。
- ^ Bulldozer design power efficiency, AMD, (August 24, 2010)
- ^ (PDF) AP 2012年1月23日閲覧。
- ^ Johan De Gelas, The Bulldozer Aftermath: Delving Even Deeper
- ^ Anand Lal Shimpi, AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
- ^ https://www.olcf.ornl.gov/wp-content/uploads/2012/01/TitanWorkshop2012_Day1_AMD.pdf
- ^ XOP and FMA4 Instruction set in SSE5, Techreport.com, (2009-05-06) 2012年1月23日閲覧。
- ^ AMD Financial Analyst Day 2010, Server Platforms Presentation, Ir.amd.com, (2010-11-09) 2012年1月23日閲覧。
- ^ (PDF) AP 2012年1月23日閲覧。
- ^ (PDF) AP 2012年1月23日閲覧。
- ^ AMD Roadmap 2012年1月23日閲覧。
- ^ AMD (2012-05-14), AMD Opteron 4200 Series Processor Quick Reference Guide, www.amd.com 2012年8月15日閲覧。
- ^ AMD (2012-05-14), AMD Opteron 6200 Series Processor Quick Reference Guide, www.amd.com 2012年8月15日閲覧。
- ^ ASUS confirms AM3+ compatibility on AM3 boards, Event.asus.com 2012年1月23日閲覧。
- ^ MSI confirms AM3+ compatibility on AM3 boards, Event.msi.com 2012年1月23日閲覧。
- ^ AM3 processors will work in the AM3+ socket, but Bulldozer chips will not work in non-AM3+ motherboards Archived December 10, 2010, at the Wayback Machine.
- ^ “AMD sued over allegedly misleading Bulldozer core count”. Ars Technica 8 November 2015閲覧。
- ^ “AMD Bulldozer 'Core' Lawsuit: AMD Settles for $12.1m, Payouts for Some”. AnandTech 19 January 2021閲覧。
- ^ “Tony Dickey and Paul Parmer, et al. v. Advanced Micro Devices”. 19 October 2019時点のオリジナルよりアーカイブ。19 January 2021閲覧。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
関連項目
[編集]参考資料
[編集]- 後藤弘茂のWeekly海外ニュースついにベールを脱いだAMDの「Bulldozer」と「Bobcat」
- 適用で8コアのAMD FXが「4コア」に!? Microsoftの「Bulldozerアーキテクチャ最適化パッチ」を試す
この項目は、まだ閲覧者の調べものの参照としては役立たない、コンピュータに関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(P:コンピュータ)。 |