
p値
帰無仮説の有意性検定において、p値(ピーち、p-value[注 1])は、帰無仮説が正しいという仮定の下で、実際に観察された結果と少なくとも同じくらい極端な検定結果を得る確率である[2][3]。p値が非常に小さいことは、そのような極端な観測結果は帰無仮説の下では極めて起こりにくいことを意味する。多くの定量的な分野の学術出版物では、統計的検定の p値が一般的に報告されているにもかかわらず、p値の誤った解釈や p値の誤用が広く見られ、数学やメタサイエンスの主要な課題となっている[4][5]。2016年、アメリカ統計学会(ASA)は正式な声明を発表し、「p値は、研究対象となった仮説が正しい確率や、データが偶然だけで生じた確率を測定するものではない」と述べ、「p値、すなわち統計的有意性は、効果の大きさや結果の重要性を測定するものではない」または「モデルや仮説に関する証拠」ではないとした[6]。しかし、ASAのタスクフォースは2019年に、統計的有意性と再現性に関する声明を発表し、「p値および有意性検定は、適切に用いられ解釈された場合、データから導き出される結論の厳密性を高めることができる」と結論づけている[7]。
基本概念
[編集]統計学では、ある研究における観測データ を表す確率変数の集合について、未知の確率分布に関するあらゆる推測を統計的仮説(statistical hypothesis)と呼ぶ。統計的検定の目的が、一つだけ述べた仮説が妥当であるかどうかを検証することであって、別の特定の仮説を検証することではない場合、そのような検定は帰無仮説検定(null hypothesis test、棄却検定とも)と呼ばれる。

定義上、統計的仮説とは、分布の何らかの特徴を指すものであり、帰無仮説とは、その特徴が存在しないというデフォルト仮説を指す。通常、帰無仮説は、関心のある母集団の何らかのパラメータ(相関や平均値の差など)が 0 であるという仮説である。その仮説は、 の確率分布を正確に特定する場合もあれば、 がある分布のクラスに属することだけを特定する場合もある。多くの場合、データは単一の数値統計( など)に単純化され、その周辺確率分布は研究における主な関心事と密接に関連している。

p値は、選定した統計量 の観測結果の統計的有意性を定量化するために、帰無仮説検定の文脈で使用される[注 2]。p値が低いほど、帰無仮説が正しい場合に、その結果を得る確率が低いことを意味する。帰無仮説を棄却できる場合、その結果は統計的に有意(statistically significant)であると見なされる。他の条件がすべて同じであれば、p値が小さいほど、帰無仮説を否定するより強い証拠と見なされる。
大まかに言えば、帰無仮説の棄却は、それとは反対の十分な証拠があることを意味する。
一例として、「ある要約統計量 が標準正規分布 に従う」という帰無仮説が立てられた場合、この帰無仮説を棄却するということは、(1) の平均が 0 ではない、(2) の分散が 1 ではない、(3) が正規分布に従わない、のいずれかを意味する可能性がある。同じ帰無仮説に対する異なる検定は、対立仮説に対しする感度がそれぞれ異なる。しかし、3つの対立仮説すべてが帰無仮説を棄却でき、その分布が正規分布で分散が 1であると分かっていたとしても、帰無仮説検定では、平均が非 0 の値のうち、どれが最も妥当であるかはわからない。同じ確率分布に従う独立した観測値が多ければ多いほど、その検定の精度は向上し、平均値を正確に決定し、それが 0 でないことを示す精度も高くなる。それだけでなく、この偏差の現実世界あるいは科学的な妥当性の評価に与えられる重みも高まる。

定義と解釈
[編集]定義
[編集]p値は、帰無仮説の下で、実際の検定統計量と少なくとも同じくらい極端な検定統計量が得られる確率である。未知の分布 から観測された検定統計量 を考える。この場合、p値 は、帰無仮説 が真である場合に、検定統計量が と同じくらい「極端」な値になる事前確率である。すなわち、



- 検定統計量の分布が右片側の場合、
- 検定統計量の分布が左片側の場合、
- 検定統計量の分布が両側の場合となる。もし の分布が 0 を中心に対称であれば、 となる。




解釈
[編集]実践的な統計学者がもっとも避けるべきと考える過誤(主観的なもの)は第一種の過誤である。数学理論の第一の要件は、第一種の過誤を犯す確率が、あらかじめ定められた数 α(たとえば α = 0.05 や 0.01 など)に等しい(またはほぼ等しい、または超えない)ことを保証する検定基準を導き出すことである。この数字を有意水準と呼ぶ。—Jerzy Neyman、"The Emergence of Mathematical Statistics"[8]
有意差検定では、p値が事前に設定した閾値 を下回る場合、帰無仮説 は棄却される。この は、水準または有意水準(significance level)と呼ばれる。 はデータから導かれるものではなく、データを調べる前に研究者が設定する。 は通常 0.05 に設定されるが、より小さな 水準が使用されることもある。2018年、ダニエル・ベンジャミン率いる統計学者グループが、統計的有意性の世界標準値として 0.005 を採用する提案をした[9]。

独立したデータセットに基づく異なる p値どうしは、たとえばフィッシャーの結合確率検定を使用して組み合わせることができる。
分布
[編集]p値は、選定された検定統計量 の関数であるため、確率変数である。帰無仮説が の確率分布を正確に定義している場合(例: ここで は唯一のパラメータ)、その分布が連続的である場合、帰無仮説が真であれば p値は 0 から 1 の間の一様分布となる。 の真偽に関わらず、p値は固定値ではない。同じ検定を新しいデータで独立して繰り返した場合、通常、各反復で異なる p値が得られる。


通常、ある仮説に関連して観察される p値は 1つだけであるため、p値は有意差検定によって解釈され、p値の分布を推定する試みはなされない。p値の集合が利用可能な場合(例:同じ主題に関する一連の研究の検証)、p値の分布は p曲線(p-curve)と呼ばれることがある[10]。p曲線は、出版バイアスや p値ハッキングを検出するなど、科学文献の信頼性を評価するために使用されることがある[10][11]。
複合仮説の分布
[編集]パラメトリック仮説検定問題では、単純仮説または点仮説とは、パラメータの値が単一の数値であると想定する仮説である。これに対し、複合仮説(composite hypothesis (en:英語版) )では、パラメータは一連の数値によって表される。帰無仮説が複合仮説である場合(または統計量の分布が離散的である場合)、帰無仮説が真であれば、0 から 1 までの任意の数値以下となる p値を得る確率は、それらの数を依然として下回る[訳語疑問点]。言い換えれば、帰無仮説が真である場合、非常に小さな p値は比較的発生しにくく、また p値が より小さい場合、帰無仮説を棄却することで 水準での有意差があるという状況に変わりはない[12][13]。
たとえば、ある分布が正規分布で平均値 0 以下であるという帰無仮説を、平均値が 0 より大きいという対立仮説(、分散は既知)に対して検定する場合、その帰無仮説は適切な検定統計量の正確な確率分布を特定しない。この例では、片側一標本 Z検定に属する Z統計量となる。理論平均値のとりうる値ごとに、Z検定統計量は異なる確率分布を持つ。このような状況では、p値は最も不利な帰無仮説の状況(通常は帰無仮説と対立仮説の境界線上にある)に基づいて定義される。この定義により、p値および α水準が相互に補完しあうことが保証される。 は、p値が 0.05 を下回る場合にのみ帰無仮説が棄却されることを意味し、その仮説検定の第一種過誤率は実際に 0.05 が上限となる。


使用法
[編集]p値は、統計的仮説検定、特に帰無仮説の有意差検定において広く用いられている。この方法では、研究を行う前に、まずモデル(帰無仮説)と有意水準 α(一般的に0.05)が選択される。データを分析した後、p値が αより小さい場合、観察されたデータが帰無仮説と十分に矛盾していると見なされるため、帰無仮説は棄却される。しかし、これは帰無仮説が誤りであるということを証明するものではない。p値はそれ自体で仮説の確からしさを示すものではない。むしろ、p値は、帰無仮説を棄却すべきかどうかを判断する道具である[14]。
誤用
[編集]アメリカ統計学会(ASA)によると、p値は誤用され、誤って解釈されることが多いことが広く認められている[3]。特に批判されているのは、他の裏付けとなる証拠がない場合に、名目上の p値が 0.05 未満であれば対立仮説を受け入れるという慣行である。p値は、データが特定の統計モデルとどの程度矛盾しているかを評価するときに有用であるが、「研究の計画、測定の質、研究対象の現象に関する外的証拠、データ分析の基礎となる仮定の妥当性」などの状況的要因も考慮しなければならない[3]。もう一つの懸念は、p値が帰無仮説が真である確率と誤解されることが多いことである[3][15]。
一部の統計学者は、p値を放棄し[3]、信頼区間[16][17]、尤度比[18][19]、ベイズ因子[20][21][22]などの他の推論統計に焦点を当てることを提案しているが、これらの代替案の実現可能性は激しい議論されている[23][24]。また、固定された有意水準の閾値を撤廃し、p値を帰無仮説に対する証拠の強さを示す連続的な指標として解釈すべきだという意見もある[25][26]。また、偽陽性(すなわち、実質効果がない確率)のリスクを事前に設定した閾値(例:5%)未満に抑えるために必要な実質効果の事前確率を p値とともに報告するという提案もあった[27]。
そうとはいえ、2019年にASAのタスクフォースが招集され、科学的研究における統計的手法の使用、特に仮説検定と p値、および再現可能性との関連性について検討された[7]。タスクフォースは、「不確実性のさまざまな尺度は互いに補完し合うものであり、単一の尺度ですべての目的を果たすことはできない。」と述べ、その一つとして p値をあげている。また、p値は特定の値について検討する場合だけでなく、ある閾値と比較する場合にも有用な情報を提供できることを強調している。一般的に「p値および有意差検定は、適切に用いられ解釈された場合、データから導き出される結論の厳密性を高めることができる」と強調している。
算出
[編集]通常、 は検定統計量である。検定統計量は、観測されたすべての値によるスカラー関数の出力である。この統計量は、t統計量や F統計量などの単一の数値を示す。したがって、検定統計量は、それを定義する関数と入力観測データの分布によって決まる分布に従う。
データが正規分布からの無作為抽出サンプルであると仮定される重要なケースでは、検定統計量の特性とその分布に関する仮説に応じて、異なる帰無仮説検定が開発されている。そのような検定には、分散が既知の正規分布の平均に関する仮説に対する z検定、分散が未知の正規分布の平均に関する仮説に対する適切な統計量 スチューデントの t分布に基づく t検定、分散に関する仮説に対する別の統計量 F分布に基づく F検定などがある。カテゴリデータ(離散データ)などの他の特性を持つデータについては、ピアソンのカイ二乗検定 (en:英語版) のような、大規模な標本に対して中心極限定理を適用して得られる適切な統計量の正規近似に基づく帰無仮説分布と、それに基づく検定統計量が構築されることがある。
このように、p値を算出するには、帰無仮説、検定統計量(片側検定と両側検定を行うかどうかの研究者の決定を含む)、および観測データが必要である。あるデータに対する検定統計量の算出は簡単であっても、帰無仮説に基づく標本分布の算出や、累積分布関数(CDF)の算出はしばしば難しい問題となる。今日では、この計算は統計ソフトウェアを使用して行われ、多くの場合、厳密な数式ではなく数値解析が使用されるが、20世紀前半から半ばにかけては数値表を用いており、これらの離散値から p値を内挿または外挿していた[要出典]。フィッシャーは、p値の表を使用する代わりに、CDFを反転させ、固定 p値に対する検定統計量の値の一覧表を発表した。これは、分位関数(逆CDF)を計算することと同じである。
例
[編集]コインの公正性の検定
[編集]統計検定の一例として、コイン投げが公正か(表と裏が出る確率が等しい)、不正に偏っているか(どちらか一方の面が出る確率がより高い)を調べる実験が行われた。
実験ではコインを20回投げ、うち表が14回出た。全データ は、表(Head)あるいは裏(Tail)の20個の記号からなる。着目する統計量は、表が出た総数 である。帰無仮説は、コインは公正であり、コイン投げは互いに独立であるというものである。コインが表に偏っている可能性について実際に関心があるため、右側検定を考慮することになる。この場合、結果の p値は、20回の公正なコイン投げのうち少なくとも14回が表になる確率である。この確率は、二項係数から次のように計算できる。
![{\displaystyle {\begin{aligned}&\Pr(14{\text{ heads}})+\Pr(15{\text{ heads}})+\cdots +\Pr(20{\text{ heads}})\\&={\frac {1}{2^{20}}}\left[{\binom {20}{14}}+{\binom {20}{15}}+\cdots +{\binom {20}{20}}\right]={\frac {60\,460}{1\,048\,576}}\approx 0.058.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f2eebd3ba4473859aaacc3235a3929b3bf3b2bb)
この確率は、 表に有利な極端な結果のみを考慮した p値である。これは、片側検定(one-tailed test)と呼ばれる。しかし、表か裏のどちらかの方向に偏り、どちらに有利になるかに関心をもつこともある。表または裏のいずれかに有利な偏差を考慮した両側 p値(two-tailed p-value)を、代わりに計算することができる。公正なコインの場合、二項分布は対称形となるため、両側 p値は単純に、前述した片側 p値の2倍となる。この両側 p値は 0.115 である。上記の例は次のように計算することができる。
- 帰無仮説 (H0):コインは公正であり、Pr(heads) = 0.5 である
- 検定統計量:表が出た回数
- α水準(有意水準;指定した有意差の閾値):0.05
- 観測値 O:20回投げ、表は14回
- H0 における観測値 O の両側 p値: 2 × min(Pr(表の回数 ≥ 14回), Pr(表の回数 ≤ 14回)) = 2 × min(0.058, 0.978) = 2 × 0.058 = 0.115
Pr(表の回数 ≤ 14回) = 1 − Pr(表の回数 ≥ 14回) + Pr(表の回数 = 14) = 1 − 0.058 + 0.036 = 0.978 となる。ただし、この二項分布は対称性があるため、2つの確率のうち小さい方を見つける計算は不要である。この例では、計算した p値は 0.05 を上回っており、コインが公正であれば、95%の確率で起こる範囲内にデータが収まることを意味する。したがって、優位水準 0.05 で帰無仮説は棄却されない。
しかし、表がもう1つ出ていた場合、p値(両側)は 0.0414(4.14%)となり、この例では、有意水準 0.05 で帰無仮説が棄却される。
多段階実験の計画
[編集]コインの公正性を検定するための多段階実験を考えると、「極端」という言葉には2つの異なる意味があることが明らかになる。実験が次のように設計されていると仮定する。
- コインを2回投げる。2回とも表または裏が出た場合、実験は終了する。
- そうでない場合は、さらに4回コインを投げる。
この実験には、表2回、裏2回、表5回と裏1回、...、表1回と裏5回という7種類の結果がある。いま「表3回と裏3回」という結果について p値を計算する。
検定統計量として「表/裏」を用いる場合、帰無仮説の下では、両側 p値は正確に 1、左片側 p値は正確に 19/32、右片側 p値も同様となる。
「表3回と裏3回」と同じかそれよりも低い確率の結果がすべて「少なくとも同じくらい極端」とみなされる場合、p値は正確に 1/2 となる。
しかし、何が起こってもコインを6回だけ投げると計画した場合、p値の2番目の定義から、「表3回と裏3回」の p値は正確に 1 となる。
このように、「少なくとも同じくらい極端」という p値の定義は状況に大きく依存し、実際には起こらなかったことも含め、実験者が「計画した」内容によっても異なる。
歴史
[編集]
.jpg)


P値の算出は1700年代に遡り、人の出生時の性比を、男女間の出生確率が等しいという帰無仮説と比較した際の、統計的有意性を算出するために使用されていた[28]。ジョン・アーバスノットは1710年にこの問題について研究し、1629年から1710年までの82年間のロンドンの出生記録を調査した[29][30][31][32]。どの年も、ロンドンで生まれた男児の数は女児の数を上回っていた。男児と女児の出生が等しく起こると見なすと、観察された結果の確率は 1/282、つまり1/4,836,000,000,000,000,000,000,000である。これは現代の言葉で言う p値である。これは極めて小さな値であり、アーバスノットは、これを偶然ではなく神の摂理によるものだと結論づけ、「このことから、世界を支配するのは偶然ではなく、創造であるという結論が導き出される。」と述べた。現代的な言い方をすれば、彼は p = 1/282 の有意水準で、男児と女児の出生が同じ確率であるという帰無仮説を棄却した。アーバスノットのこの研究と他の研究は、「… 初めて有意差検定が用いられた…[33]」、「統計的有意性に関する推論の最初の例[34]」であり、「…おそらくノンパラメトリック検定の最初の公表された報告…[30]」として、特に符号検定の最初の報告として知られている。詳細は符号検定 § 歴史を参照のこと。
同じ疑問は後に、ピエール=シモン・ラプラスによって取り上げられ、ラプラスは代わりにパラメトリック検定(parametric test)を行い、二項分布に基づいて男性の出生数をモデル化した[35]。
1770年代、ラプラスは50万人近い出生統計を検討した。統計では男児の数が女児の数を上回っていた。彼は p値の計算から、極端な現象は現実のものだが説明できない効果であると結論づけた。
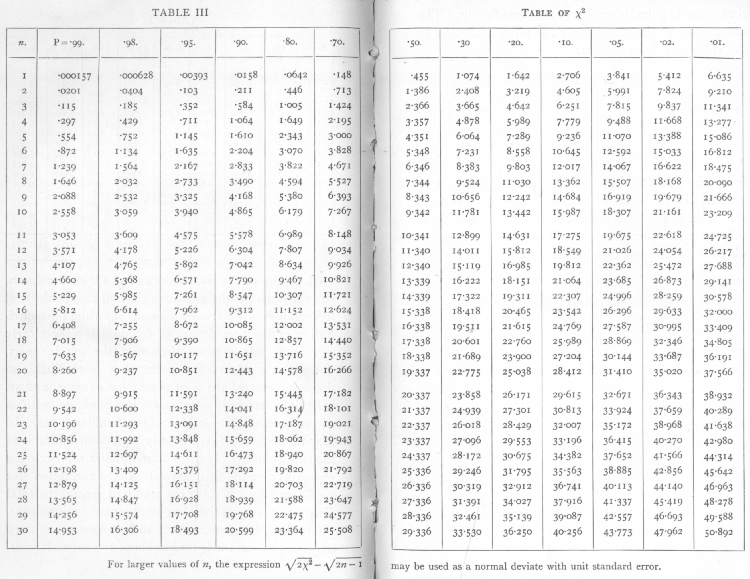
p値は、カール・ピアソンが、カイ二乗分布を用いた「ピアソンのカイ二乗検定」で初めて正式に導入し、大文字の P で表記した[36]。現在では、カイ二乗分布の p値(さまざまな χ2 値と自由度)は P と表記され、Elderton (1902)で算出され、Pearson (1914:xxxi–xxxiii, 26–28, Table XII) にまとめられた。
ロナルド・フィッシャーは統計における p値の使い方を正式化し、普及させ[37][38]、この問題に対する彼の研究方法において中心的な役割を果たした[39]。フィッシャーは、影響力の大きな著書『Statistical Methods for Research Workers(研究者のための統計的方法)』(1925年)の中で、偶然に超えられる確率が20分の1となる水準 p = 0.05 を統計的有意性の限界として提案し、これを(両側検定として)正規分布に適用して、統計的有意性のための(正規分布における)2標準偏差のルールを生みだした[40][注 3][41]。(参照 68-95-99.7則)
さらに、Elderton の手法に似た数値表も算出したが、より重要なのは、χ2 と p の役割が逆転したことである。つまり、χ2(および自由度 n)のさまざまな値について p を計算するのではなく、特定の p値、具体的には 0.99、0.98、0.95、0.90、0.80、0.70、0.50、0.30、0.20、0.10、0.05、0.02、0.01 に対応する χ2 値を計算した[42]。これにより、χ2 の計算値をカットオフ値と比較できるようになり(p値自体を計算し、報告するのではなく)、そして p値(特に0.05、0.02、0.01)をカットオフ値とすることが推奨された。その後、Fisher & Yates (1938) により同様の表がまとめられ、この手法が定着した[41]。
実験の設計と解釈における p値の適用例として、フィッシャーは、次の著書『The Design of Experiments(実験計画法)』(1935年)で、p値の典型的な例として知られる「紅茶の違いのわかる婦人」の実験を紹介した[43]。
ある女性(ミュリエル・ブリストル)が、ミルクを先にカップに注いで紅茶を足す方法と、紅茶を先にカップに注いでミルクを足す方法との違いを味で区別できると主張するのを評価するため、8つのカップが順番に彼女に提示された。4杯は一方の方法で、4杯はもう一方の方法で用意され、彼女はそれぞれのカップにどのように紅茶が入れられたかを判断するように求められた(それぞれ4杯ずつあることは知っていた)。この場合、帰無仮説は「彼女に特別な能力はない」であり、検定方法はフィッシャーの正確確率検定で、p値は であった。フィッシャーは、すべてが正しく分類された場合は帰無仮説を棄却することに同意した(偶然による可能性は非常に低いと考えた)。実際の実験では、ブリストルは8つのカップをすべて正しく分類した。

フィッシャーは p = 0.05 という基準を再度述べ、その根拠を説明した[44]。
有意水準の基準として5%を用いるのは、実験者にとって一般的であり、便利でもある。つまりこの基準に達しない結果をすべて無視し、偶然が実験結果にもたらした変動の大部分を以降の議論から排除するという意味で、実験者にとって都合が良い。
また、彼はこの閾値を実験計画にも適用し、もし6つのカップ(各3杯)しか提示されていなかった場合、分類が完全であったとしても、p値は にしかならず、この有意水準を満たすことはないだろうと指摘している[44]。フィッシャーはまた、帰無仮説が正しいと仮定した場合、データと同程度の極端な値の長期的な比率として p値を解釈する重要性を強調した。

フィッシャーは、著書の後の版で、科学的な統計的推論における p値の使い方をネイマン・ピアソン法と明確に比較し、それを「受け入れ手順」と呼んだ[45]。フィッシャーは、5%、2%、1%といった固定の水準は簡便であるが、正確な p値も使用でき、さらなる実験によって証拠の強さを改め、見直すことができると強調した。その一方、決定手順は明確な意思決定を必要とし、その結果、不可解な行動につながり、またその手順は過誤のコストに基づいており、科学的研究には適用できないと指摘した。
関連指標
[編集]E値は2つの意味があり、どちらも p値に関連し、多重検定において役割を果たしている。第一に、p値に代わる一般的で、より頑強な代替値で、実験の任意継続にも対応できる。第二に、「期待値」を簡約して表すために使用され、帰無仮説が真であると仮定した場合に、実際に観測された値と少なくとも同じくらい極端な検定統計量が得られることが期待される回数である[46]。この期待値は、検定回数と p値の積である。
q値は、偽陽性発見率に関する p値の類似値である[47]。これは多重仮説検定で使用され、偽陽性率を最小限に抑えながら、統計的検出力を維持するために使われる[48]。
方向性確率(pd)は、ベイズ統計学における p値の数値的等価である[49]。これは、事後分布のうち中央値と同じ符号を持つものの割合に相当し、通常は50%から100%の間で変化し、効果が正であるか負であるかの確実性を表す。
第二世代 p値は、極めて小さな、実質的に無関係な効果量を有意と見なさない、p値の概念の拡張である[50]。
脚注
[編集]注釈
[編集]- ^ 用語のイタリック体、大文字、ハイフンの使用法はさまざまである。たとえば、AMAスタイルでは"P value"、APAスタイルでは"p value"、アメリカ統計学会(ASA)では"p-value"と表記する。いずれの場合も「p」は確率(probability)を表す。[1]
- ^ 結果の統計的有意性は、結果が現実世界でも当てはまることを意味するわけではない。たとえば、ある薬が統計的に有意な効果を持っていたとしても、その効果が小さすぎて意味がないこともある。
- ^ より具体的に言えば、p = 0.05 は正規分布(両側検定)の場合、約 1.96 標準偏差に相当し、2標準偏差は偶然に超える可能性が約 1/22、つまり p ≈ 0.045 に相当する。フィッシャーはこれらの近似値について言及している。
出典
[編集]- ^ “ASA House Style”. Amstat News. American Statistical Association. 2022年2月5日閲覧。
- ^ Aschwanden C (2015年11月24日). “Not Even Scientists Can Easily Explain P-values”. FiveThirtyEight. 25 September 2019時点のオリジナルよりアーカイブ。11 October 2019閲覧。
- ^ a b c d e Wasserstein RL; Lazar NA (7 March 2016). “The ASA's Statement on p-Values: Context, Process, and Purpose”. The American Statistician 70 (2): 129–133. doi:10.1080/00031305.2016.1154108.
- ^ Hubbard R; Lindsay RM (2008). “Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing”. Theory & Psychology 18 (1): 69–88. doi:10.1177/0959354307086923.
- ^ Munafò MR; Nosek BA; Bishop DV; Button KS; Chambers CD; du Sert NP et al. (January 2017). “A manifesto for reproducible science”. Nature Human Behaviour 1 (1): 0021. doi:10.1038/s41562-016-0021. PMC 7610724. PMID 33954258.
- ^ Wasserstein, Ronald L.; Lazar, Nicole A. (2016-04-02). “The ASA Statement on p -Values: Context, Process, and Purpose” (英語). The American Statistician 70 (2): 129–133. doi:10.1080/00031305.2016.1154108. ISSN 0003-1305.
- ^ a b Benjamini, Yoav; De Veaux, Richard D.; Efron, Bradley; Evans, Scott; Glickman, Mark; Graubard, Barry I.; He, Xuming; Meng, Xiao-Li et al. (2021-10-02). “ASA President's Task Force Statement on Statistical Significance and Replicability”. Chance (Informa UK Limited) 34 (4): 10–11. doi:10.1080/09332480.2021.2003631. ISSN 0933-2480.
- ^ Neyman, Jerzy (1976). “The Emergence of Mathematical Statistics: A Historical Sketch with Particular Reference to the United States”. In Owen, D.B.. On the History of Statistics and Probability. Textbooks and Monographs. New York: Marcel Dekker Inc. p. 161
- ^ Benjamin, Daniel J.; Berger, James O.; Johannesson, Magnus; Nosek, Brian A.; Wagenmakers, E.-J.; Berk, Richard; Bollen, Kenneth A.; Brembs, Björn et al. (1 September 2017). “Redefine statistical significance”. Nature Human Behaviour 2 (1): 6–10. doi:10.1038/s41562-017-0189-z. hdl:10281/184094. PMID 30980045.
- ^ a b Head ML; Holman L; Lanfear R; Kahn AT; Jennions MD (March 2015). “The extent and consequences of p-hacking in science”. PLOS Biology 13 (3): e1002106. doi:10.1371/journal.pbio.1002106. PMC 4359000. PMID 25768323.
- ^ Simonsohn U; Nelson LD; Simmons JP (November 2014). “p-Curve and Effect Size: Correcting for Publication Bias Using Only Significant Results”. Perspectives on Psychological Science 9 (6): 666–681. doi:10.1177/1745691614553988. PMID 26186117.
- ^ Bhattacharya B; Habtzghi D (2002). “Median of the p value under the alternative hypothesis”. The American Statistician 56 (3): 202–6. doi:10.1198/000313002146.
- ^ Hung HM; O'Neill RT; Bauer P; Köhne K (March 1997). “The behavior of the P-value when the alternative hypothesis is true”. Biometrics 53 (1): 11–22. doi:10.2307/2533093. JSTOR 2533093. PMID 9147587.
- ^ Nuzzo R (February 2014). “Scientific method: statistical errors”. Nature 506 (7487): 150–152. Bibcode: 2014Natur.506..150N. doi:10.1038/506150a. PMID 24522584.
- ^ Colquhoun D (November 2014). “An investigation of the false discovery rate and the misinterpretation of p-values”. Royal Society Open Science 1 (3): 140216. arXiv:1407.5296. Bibcode: 2014RSOS....140216C. doi:10.1098/rsos.140216. PMC 4448847. PMID 26064558.
- ^ Lee DK (December 2016). “Alternatives to P value: confidence interval and effect size”. Korean Journal of Anesthesiology 69 (6): 555–562. doi:10.4097/kjae.2016.69.6.555. PMC 5133225. PMID 27924194.
- ^ Ranstam J (August 2012). “Why the P-value culture is bad and confidence intervals a better alternative”. Osteoarthritis and Cartilage 20 (8): 805–808. doi:10.1016/j.joca.2012.04.001. PMID 22503814.
- ^ Perneger TV (May 2001). “Sifting the evidence. Likelihood ratios are alternatives to P values”. BMJ 322 (7295): 1184–1185. doi:10.1136/bmj.322.7295.1184. PMC 1120301. PMID 11379590.
- ^ Royall R (2004). “The Likelihood Paradigm for Statistical Evidence” (英語). The Nature of Scientific Evidence. pp. 119–152. doi:10.7208/chicago/9780226789583.003.0005. ISBN 9780226789576
- ^ Schimmack U (30 April 2015). “Replacing p-values with Bayes-Factors: A Miracle Cure for the Replicability Crisis in Psychological Science”. Replicability-Index. 7 March 2017閲覧。
- ^ Marden JI (December 2000). “Hypothesis Testing: From p Values to Bayes Factors”. Journal of the American Statistical Association 95 (452): 1316–1320. doi:10.2307/2669779. JSTOR 2669779.
- ^ Stern HS (16 February 2016). “A Test by Any Other Name: P Values, Bayes Factors, and Statistical Inference”. Multivariate Behavioral Research 51 (1): 23–29. doi:10.1080/00273171.2015.1099032. PMC 4809350. PMID 26881954.
- ^ Murtaugh PA (March 2014). “In defense of P values”. Ecology 95 (3): 611–617. Bibcode: 2014Ecol...95..611M. doi:10.1890/13-0590.1. PMID 24804441.
- ^ Aschwanden C (7 March 2016). “Statisticians Found One Thing They Can Agree On: It's Time To Stop Misusing P-Values”. FiveThirtyEight. 2016年3月9日閲覧。
- ^ Amrhein V; Korner-Nievergelt F; Roth T (2017). “The earth is flat (p > 0.05): significance thresholds and the crisis of unreplicable research”. PeerJ 5: e3544. doi:10.7717/peerj.3544. PMC 5502092. PMID 28698825.
- ^ Amrhein V; Greenland S (January 2018). “Remove, rather than redefine, statistical significance”. Nature Human Behaviour 2 (1): 4. doi:10.1038/s41562-017-0224-0. PMID 30980046.
- ^ Colquhoun D (December 2017). “The reproducibility of research and the misinterpretation of p-values”. Royal Society Open Science 4 (12): 171085. doi:10.1098/rsos.171085. PMC 5750014. PMID 29308247.
- ^ Brian E; Jaisson M (2007). “Physico-Theology and Mathematics (1710–1794)”. The Descent of Human Sex Ratio at Birth. Springer Science & Business Media. pp. 1–25. ISBN 978-1-4020-6036-6
- ^ Arbuthnot J (1710). “An argument for Divine Providence, taken from the constant regularity observed in the births of both sexes”. Philosophical Transactions of the Royal Society of London 27 (325–336): 186–190. doi:10.1098/rstl.1710.0011.
- ^ a b Conover WJ (1999). “Chapter 3.4: The Sign Test”. Practical Nonparametric Statistics (Third ed.). Wiley. pp. 157–176. ISBN 978-0-471-16068-7
- ^ Sprent P (1989). Applied Nonparametric Statistical Methods (Second ed.). Chapman & Hall. ISBN 978-0-412-44980-2
- ^ Stigler SM (1986). The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. pp. 225–226. ISBN 978-0-67440341-3
- ^ Bellhouse P (2001). “John Arbuthnot”. Statisticians of the Centuries. Springer. pp. 39–42. ISBN 978-0-387-95329-8
- ^ Hald A (1998). “Chapter 4. Chance or Design: Tests of Significance”. A History of Mathematical Statistics from 1750 to 1930. Wiley. pp. 65
- ^ Stigler SM (1986). The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. p. 134. ISBN 978-0-67440341-3
- ^ Pearson K (1900). “On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling”. Philosophical Magazine. Series 5 50 (302): 157–175. doi:10.1080/14786440009463897.
- ^ Biau, David Jean; Jolles, Brigitte M.; Porcher, Raphaël (2010). “P Value and the Theory of Hypothesis Testing: An Explanation for New Researchers”. Clinical Orthopaedics and Related Research 468 (3): 885–892. doi:10.1007/s11999-009-1164-4. ISSN 0009-921X. PMC 2816758. PMID 19921345.
- ^ Brereton, Richard G. (2021). “P values and multivariate distributions: Non-orthogonal terms in regression models” (英語). Chemometrics and Intelligent Laboratory Systems 210: 104264. doi:10.1016/j.chemolab.2021.104264.
- ^ Hubbard R; Bayarri MJ (2003), “Confusion Over Measures of Evidence (p′s) Versus Errors (α′s) in Classical Statistical Testing”, The American Statistician 57 (3): 171–178 [p. 171], doi:10.1198/0003130031856
- ^ Fisher 1925, p. 47, Chapter III. Distributions.
- ^ a b Dallal 2012, Note 31: Why P=0.05?.
- ^ Fisher 1925, pp. 78–79, 98, Chapter IV. Tests of Goodness of Fit, Independence and Homogeneity; with Table of χ2, Table III. Table of χ2.
- ^ Fisher 1971, II. The Principles of Experimentation, Illustrated by a Psycho-physical Experiment.
- ^ a b Fisher 1971, Section 7. The Test of Significance.
- ^ Fisher 1971, Section 12.1 Scientific Inference and Acceptance Procedures.
- ^ “Definition of E-value”. National Institutes of Health. 2010年5月17日閲覧。
- ^ Storey JD (2003). “The positive false discovery rate: a Bayesian interpretation and the q-value”. The Annals of Statistics 31 (6): 2013–2035. doi:10.1214/aos/1074290335.
- ^ Storey JD; Tibshirani R (August 2003). “Statistical significance for genomewide studies”. Proceedings of the National Academy of Sciences of the United States of America 100 (16): 9440–9445. Bibcode: 2003PNAS..100.9440S. doi:10.1073/pnas.1530509100. PMC 170937. PMID 12883005.
- ^ Makowski D; Ben-Shachar MS; Chen SH; Lüdecke D (10 December 2019). “Indices of Effect Existence and Significance in the Bayesian Framework”. Frontiers in Psychology 10: 2767. doi:10.3389/fpsyg.2019.02767. PMC 6914840. PMID 31920819.
- ^ An Introduction to Second-Generation p-Values Jeffrey D. Blume, Robert A. Greevy, Valerie F. Welty, Jeffrey R. Smith &William D. Dupont https://www.tandfonline.com/doi/full/10.1080/00031305.2018.1537893
{kind=link}
推薦文献
[編集]- Denworth L (October 2019). “A Significant Problem: Standard scientific methods are under fire. Will anything change?”. Scientific American 321 (4): 62–67 (63). "The use of p values for nearly a century [since 1925] to determine statistical significance of experimental results has contributed to an illusion of certainty and [to] reproducibility crises in many scientific fields. There is growing determination to reform statistical analysis... Some [researchers] suggest changing statistical methods, whereas others would do away with a threshold for defining "significant" results."
- Elderton, WP (1902). “Tables for Testing the Goodness of Fit of Theory to Observation”. Biometrika 1 (2): 155–163. doi:10.1093/biomet/1.2.155.
- Pearson, Karl (1914). “On the probability that two independent distributions of frequency are really samples of the same population, with special reference to recent work on the identity of Trypanosome strains”. Biometrika 10: 85–154. doi:10.1093/biomet/10.1.85.
- Fisher, RA (1925). Statistical Methods for Research Workers. Edinburgh, Scotland: Oliver & Boyd. ISBN 978-0-05-002170-5
- Fisher, RA (1971). The Design of Experiments (9th ed.). Macmillan. ISBN 978-0-02-844690-5
- Fisher, RA; Yates (1938). Statistical tables for biological, agricultural, and medical research. London, England. hdl:2440/10701
- Stigler SM (1986). The history of statistics : the measurement of uncertainty before 1900. Cambridge, Mass: Belknap Press of Harvard University Press. ISBN 978-0-674-40340-6
- Hubbard R; Armstrong JS (2006). “Why We Don't Really Know What Statistical Significance Means: Implications for Educators”. Journal of Marketing Education 28 (2): 114–120. doi:10.1177/0273475306288399. hdl:2092/413. オリジナルのMay 18, 2006時点におけるアーカイブ。.
- Hubbard R; Lindsay RM (2008). “Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing”. Theory & Psychology 18 (1): 69–88. doi:10.1177/0959354307086923. オリジナルの2016-10-21時点におけるアーカイブ。 2015年8月28日閲覧。.
- Stigler S (December 2008). “Fisher and the 5% level”. Chance 21 (4): 12. doi:10.1007/s00144-008-0033-3.
- Dallal, GE (2012). The Little Handbook of Statistical Practice. オリジナルの2024-04-11時点におけるアーカイブ。
- Biau DJ; Jolles BM; Porcher R (March 2010). “P value and the theory of hypothesis testing: an explanation for new researchers”. Clinical Orthopaedics and Related Research 468 (3): 885–892. doi:10.1007/s11999-009-1164-4. PMC 2816758. PMID 19921345.
- Reinhart A (2015). Statistics Done Wrong: The Woefully Complete Guide. No Starch Press. p. 176. ISBN 978-1593276201
- “The ASA President's Task Force Statement on Statistical Significance and Replicability”. Annals of Applied Statistics 15 (3): 1084–1085. (2021). doi:10.1214/21-AOAS1501.
- Benjamin, Daniel J.; Berger, James O.; Johannesson, Magnus; Nosek, Brian A.; Wagenmakers, E.-J.; Berk, Richard; Bollen, Kenneth A.; Brembs, Björn et al. (1 September 2017). “Redefine statistical significance”. Nature Human Behaviour 2 (1): 6–10. doi:10.1038/s41562-017-0189-z. hdl:10281/184094. PMID 30980045.
関連項目
[編集]- t検定 - 2つの標本の差が統計的に有意であるかどうかを検定するのに使用される統計的検定
- ボンフェローニ補正 - 多重比較問題に対処する方法の一つ
- 反帰無 - 心理データの統計分析において使用される統計値
- フィッシャー法 (統計学) - データ融合またはメタ分析(分析の分析)のための手法
- 一般化 p値 - 古典的p値のいくつかの欠点を克服した拡張
- 調和平均p値 - ファミリーワイズエラー率を制御する 多重比較問題に対処するための統計的手法
- ホルム=ボンフェローニ法 - 多重比較の問題に対処するために使用される検定方法
- 多重比較問題 - 複数の検定に対する統計学的解釈
- p-rep - 古典的な p値に代わる統計的手法の一つ (理論上の誤りが指摘された)
- p値の誤用 - 統計的有意性の誤った解釈
外部リンク
[編集]- Free online p-values calculators for various specific tests (chi-square, Fisher's F-test, etc.).
- StatQuest: P-value pitfalls and power calculations - YouTube